对于逻辑回归,如果使用平方误差函数:
J(w,b)=m1i=1∑m21 (fw,b(x(i))−y(i))2
得到的代价函数会变成一个非凸的函数,会存在很多局部的极小值,任意一个局部极小值都可能让梯度下降法收敛,所以平方误差函数不适合作为逻辑回归的代价函数。
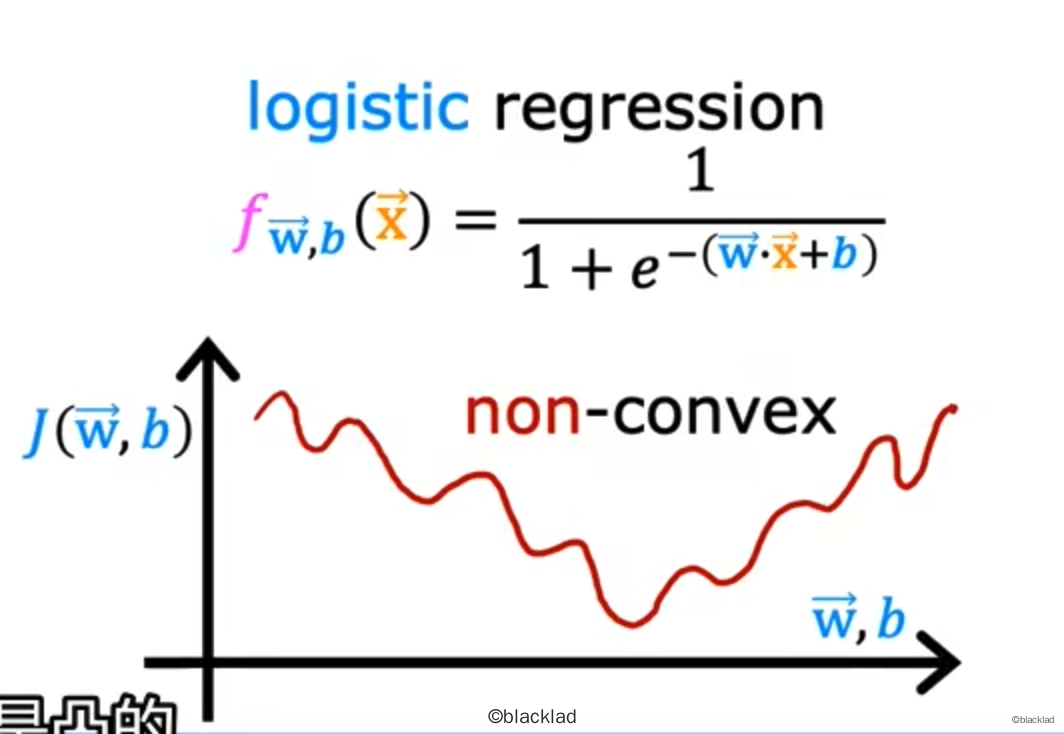
一般使用损失函数来作为逻辑回归的成本函数的一部分。损失函数表示单个训练样本的损失。
L(fw,b(x(i)),y(i))={−log(fw,b(x(i))),y(i)=1,−log(1−fw,b(x(i))),y(i)=0.
当 y(i)=1时,且 0<=fw,b(x(i))<=1,−log(fw,b(x(i)))的函数如图所示:
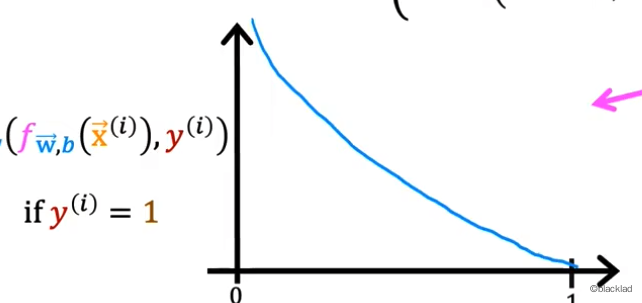
可以看到当预测值fw,b(x(i))越接近实际值y(i)=1时,损失函数的值L就越小。
当 y(i)=0时,且 0<=fw,b(x(i))<=1,−log(1−fw,b(x(i)))的函数如图所示:
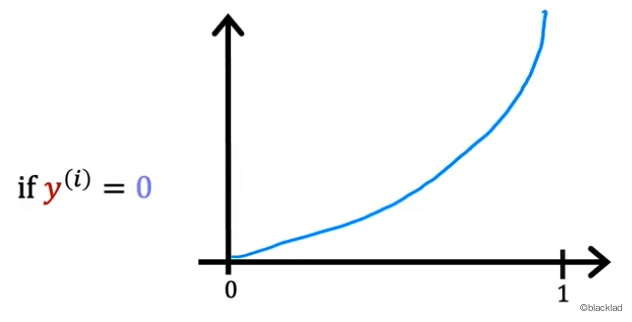
可以看到当预测值fw,b(x(i))越接近实际值y(i)=0时,损失函数的值就越小。
所以损失函数L对于任意一种情况,当预测值越接近真实值,损失值就越小,越远离真实值,损失值就越大,符合代价函数的定义。
对所有样本的损失值求和得到的代价函数为:
J(w,b)=m1i=1∑mL(fw,b(x(i)),y(i))
由于分类问题是二元分类问题,y(i)只有0/1两种取值,所以可以对损失函数的公式可以进行简化如下:
L(fw,b(x(i)),y(i))=−y(i)log(fw,b(x(i)))−(1−y(i))log(1−fw,b(x(i)))
简化后的代价函数如下:
J(w,b)=−m1i=1∑m[y(i)log(fw,b(x(i)))+(1−y(i))log(1−fw,b(x(i)))]
参考最大似然估计(maximum likehood estimation)
为了获得代价函数J(w,b)的最小值,依然可以使用梯度下降法。
先求偏导数:
∂wj∂J(w,b)=m1i=1∑m[fw,b(x(i))−y(i)]xj(i)
∂b∂J(w,b)=m1i=1∑m[fw,b(x(i))−y(i)]
即可通过梯度下降不断更新 w 和 b:
wj=wj−α[m1i=1∑m(fw,b(x(i))−y(i))xj(i)]
b=b−α[m1i=1∑m(fw,b(x(i))−y(i))]
- 知道复合函数的链式求导法则
- sigmoid 求导参考open in new window
