机器学习介绍
机器学习介绍
1 介绍
机器学习可以在没有明确编程的情况下进行学习的科学。通过机器学习可以完成很多无法通过直接编程完成的任务。
1.1 应用
机器学习在生活中有着广泛的应用
- 搜索中对网页结果的排名
- 相册中对照片的标记,包含哪个人,哪些元素
- 抖音等短视频的推荐,类似的视频
- 语音助手,语音转文字,搜索附近的美食等
行业
- 医疗领域协助医生做诊断
- 工厂中通过计算机视觉检查产品是否合格
1.2 定义
"Field of study that give scomputers the ability to learn without being explicitly programmed." -Arthur Samuel
机器学习是一门使计算机在没有明确编程的情况下即可学习的研究领域。
类型
- 监督学习
- 无监督学习
- 推荐系统
- 强化学习
2 监督学习
监督学习是机器学习中最常用的类型。学习输入(x)到输出(y)的映射关系。
在监督学习中,需要为算法提供一些带有正确答案(正确的y值)的样本来进行学习。

监督学习主要包括回归算法和分类算法。
2.1 回归算法
回归是监督学习的一种类型,用来预测一个连续的数值。
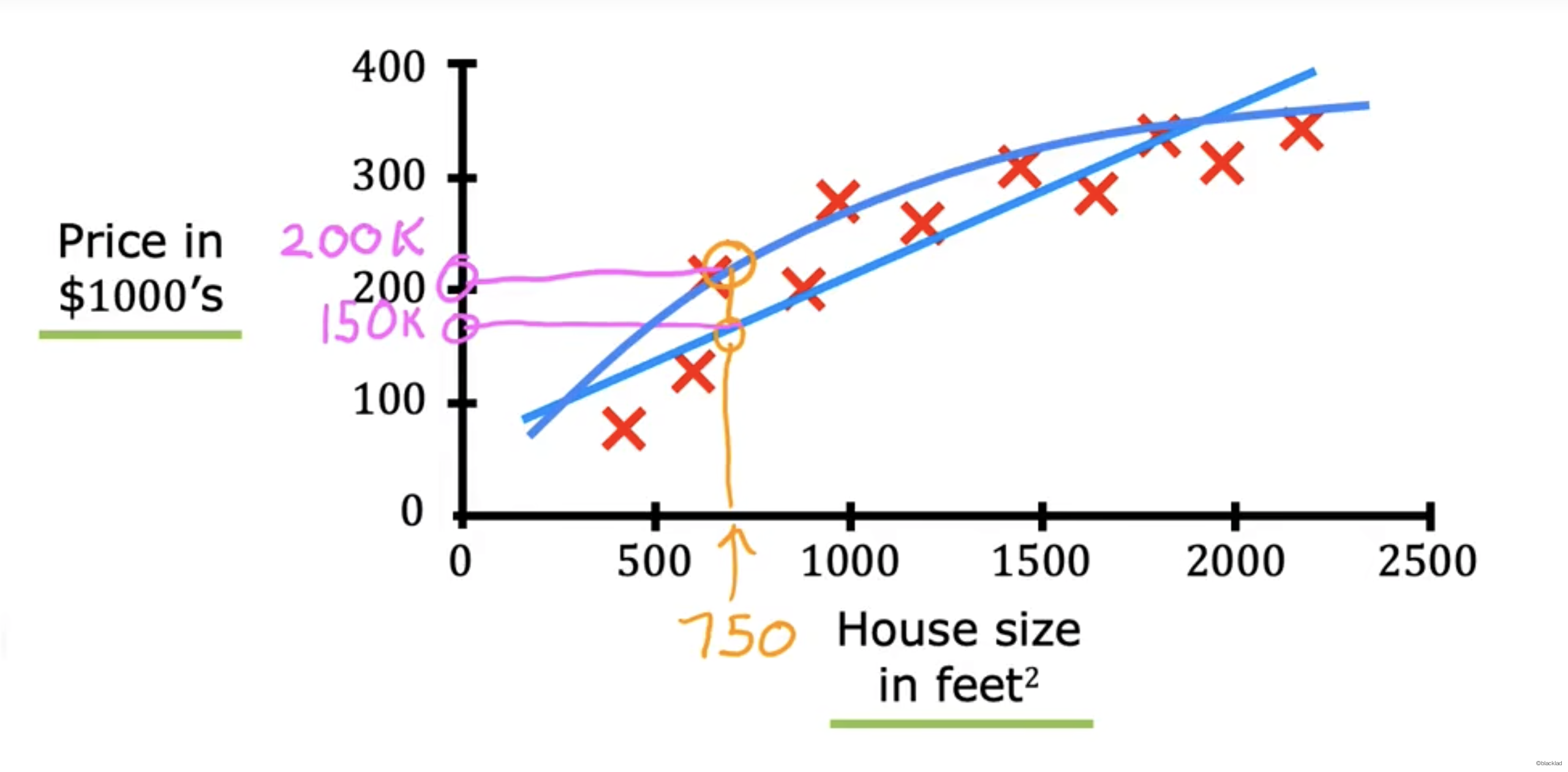
比如根据房子的大小预测价格。
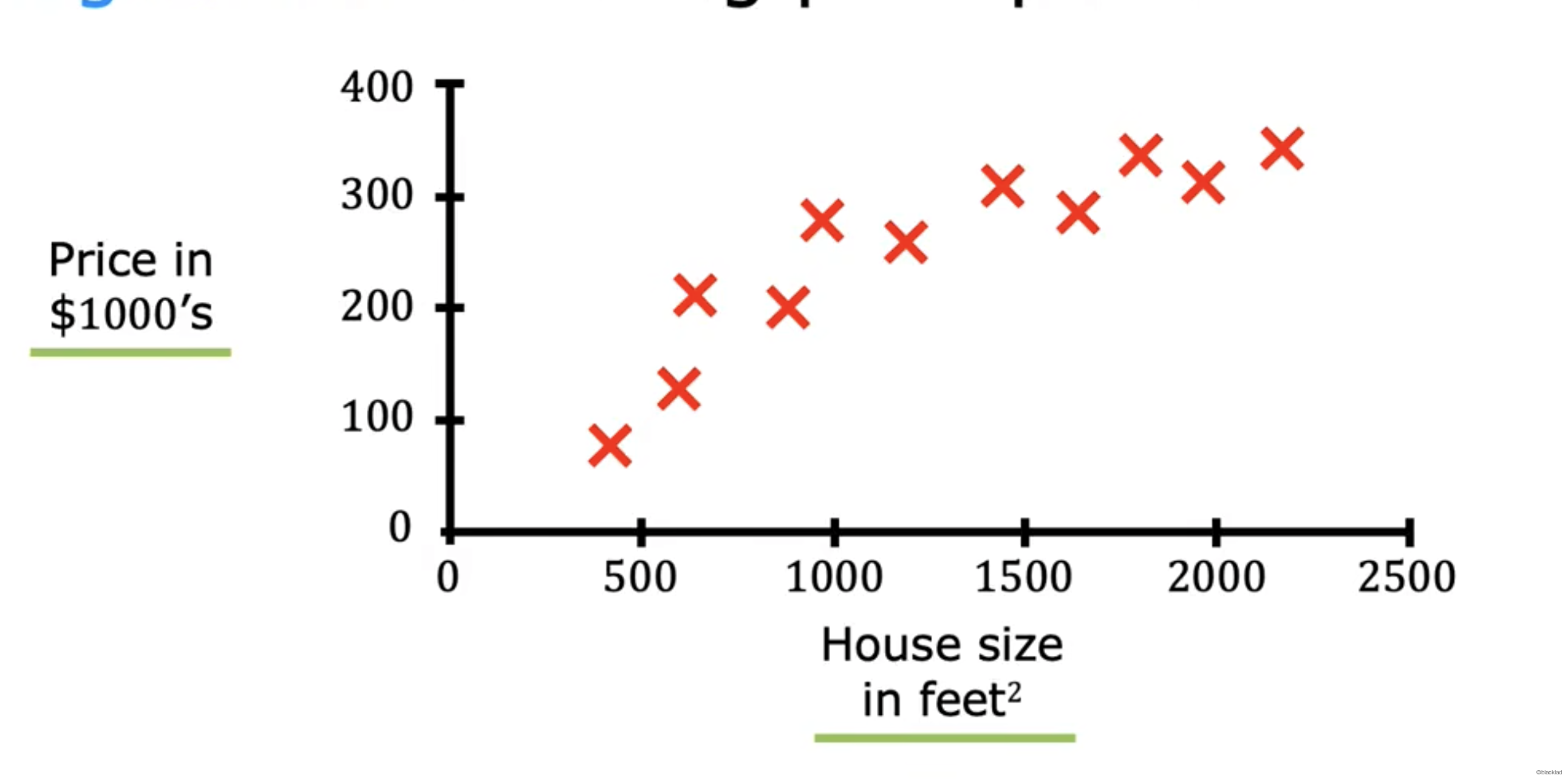
可以使用不同的算法来拟合数据,比如线性回归,曲线拟合等。
图中两根蓝线是预测的关系,对于同样大小的房屋面积,预测的房屋价格并不相同。
2.2 分类算法
分类算法是监督学习的一种类型,将输入数据分配到有限数量的类别中,输出是离散的。
比如根据肿瘤的大小判断是良性还是恶性。
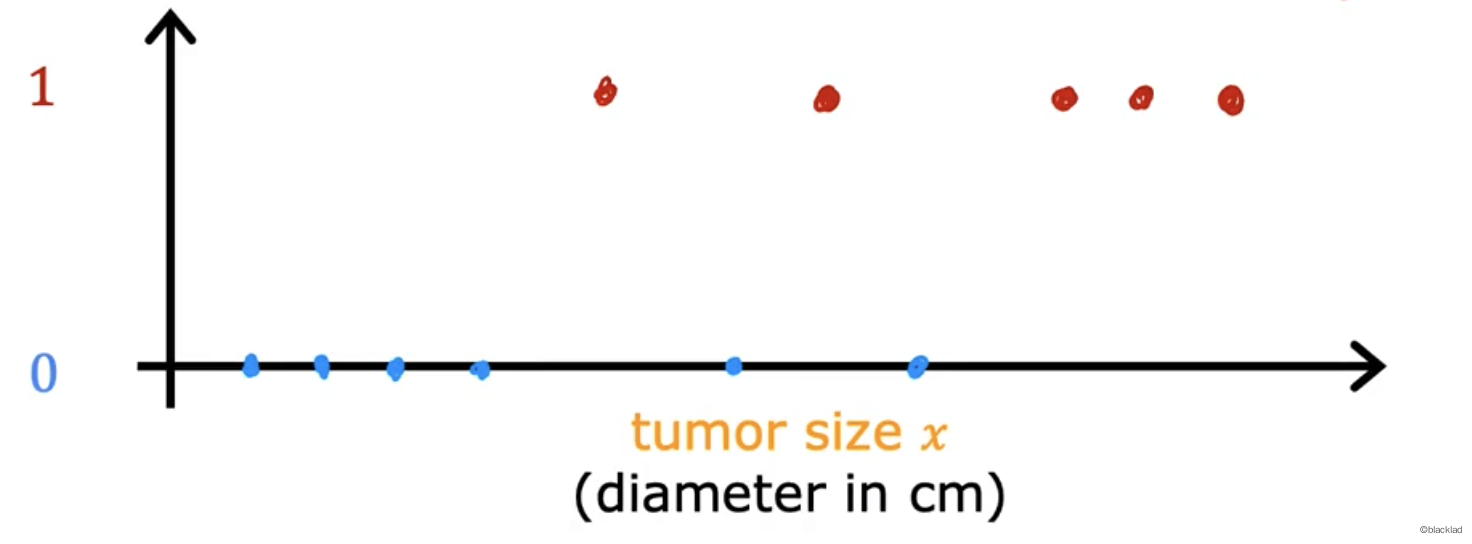
在一维的坐标轴上表示

输出特征
可以有两个或者两个以上的输出特征。
比如将肿瘤的类型再细分为1,2两种类型
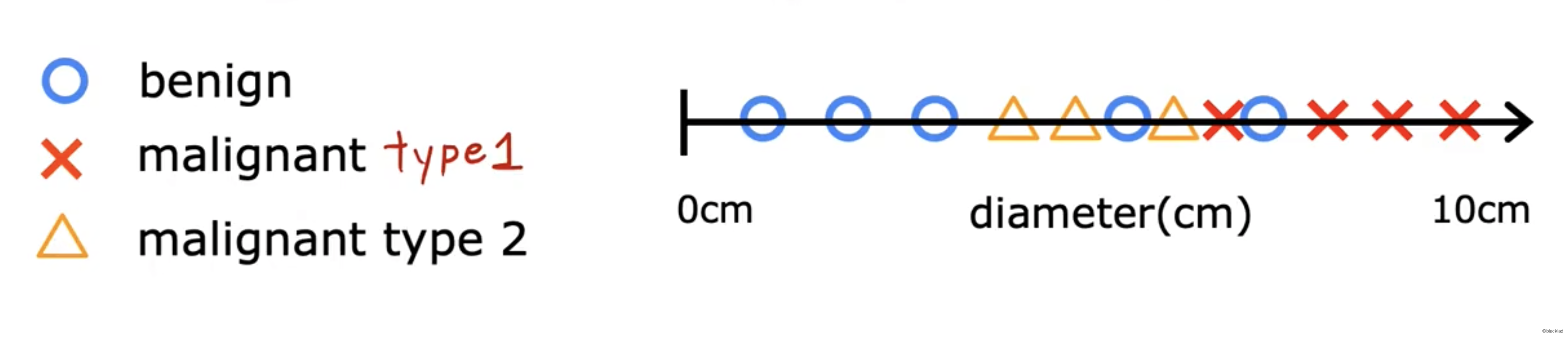
输出不一定是数字01,也可以是猫、狗。但一定是有限的集合。
输入特征
可以使用一个或多个输入特征。
如在肿瘤检测中,还可以将病人的年龄作为输入。
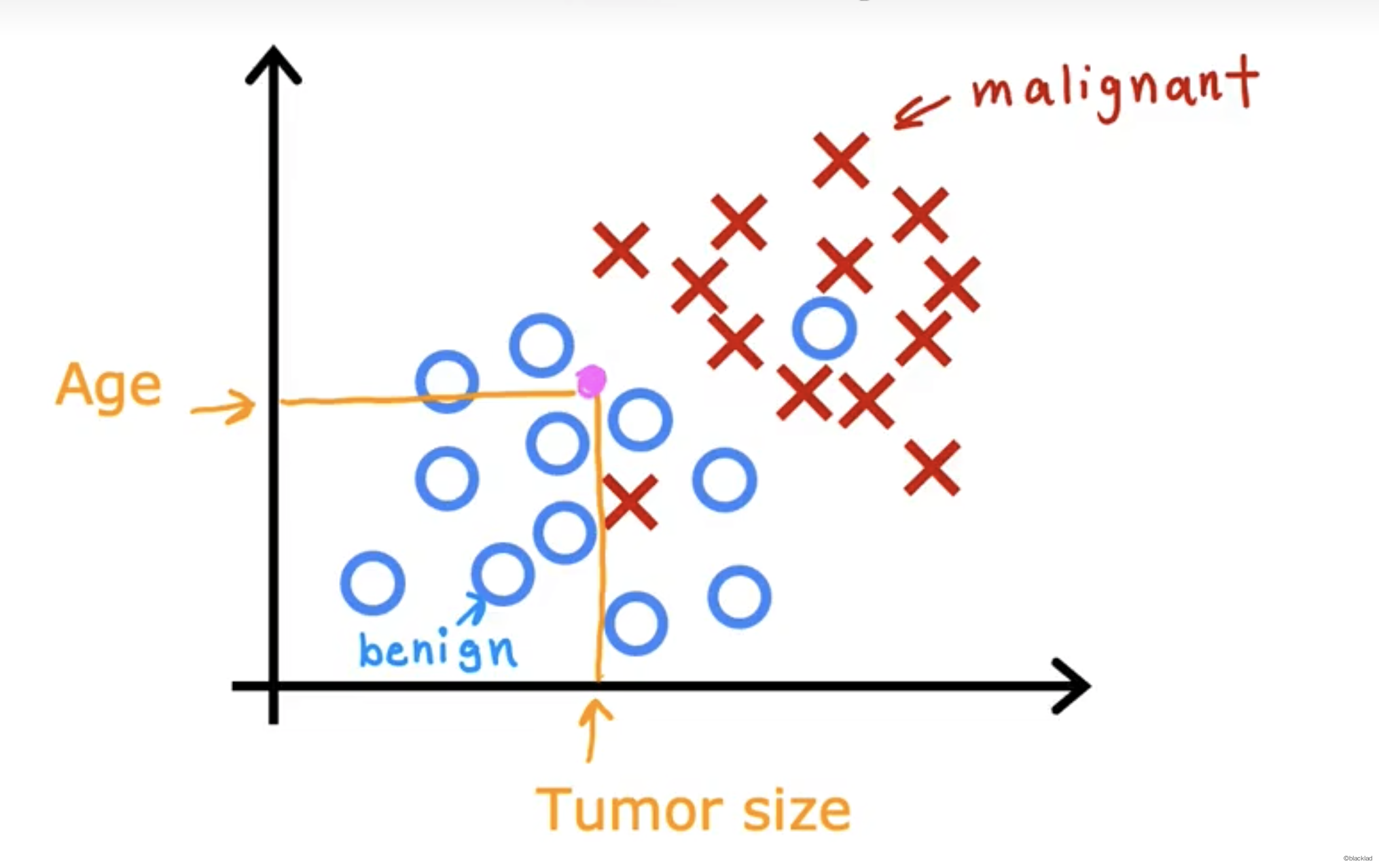
找出一条边界线,将数据分成不同的类别。

3 无监督学习
与监督学习不同,无监督学习算法不需要输出标签,给的数据只有输入x,没有输出y。
由算法从未标记的数据中分组,找到某种结构、模式或者感兴趣的信息。
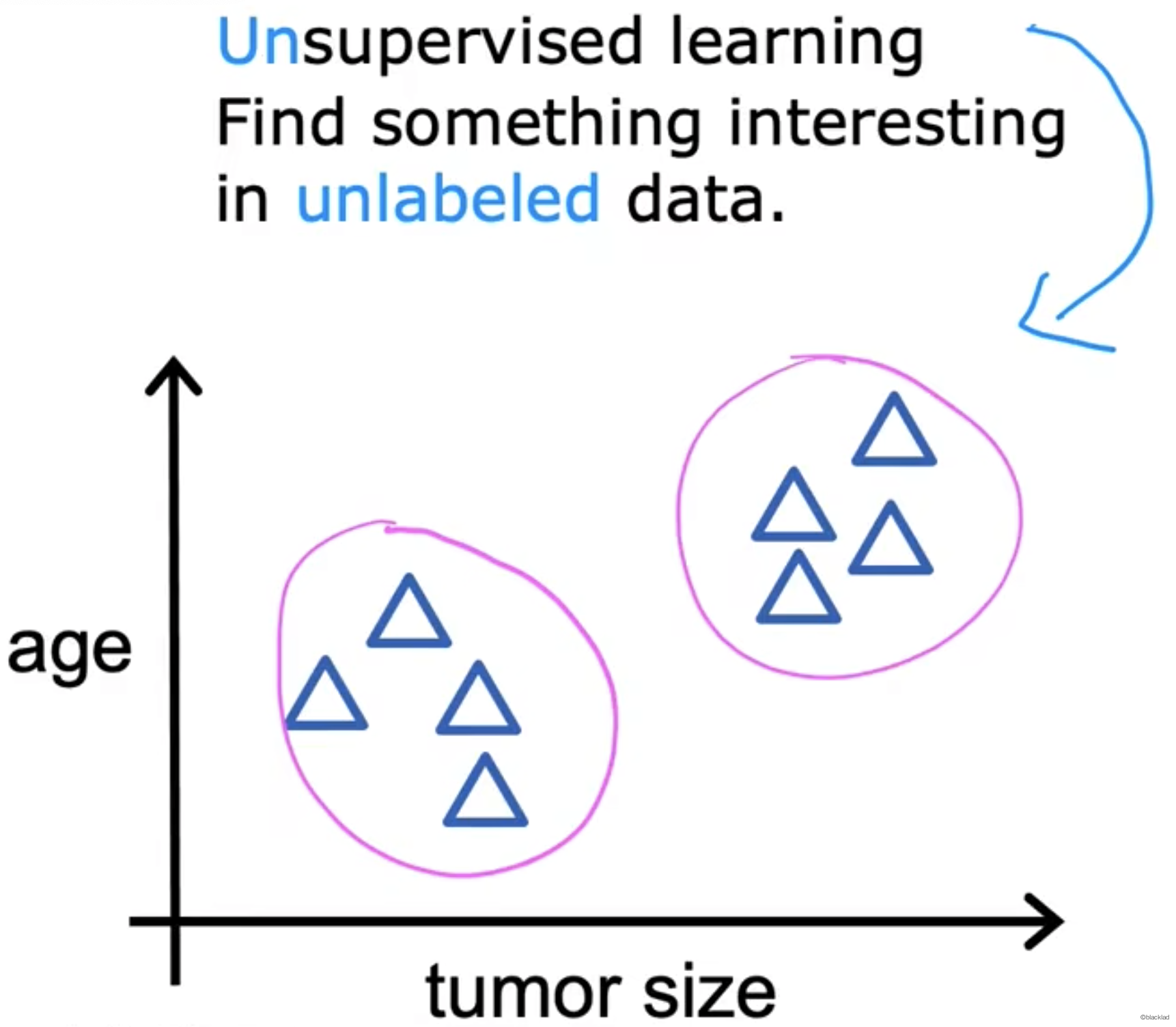
主要包括
聚类算法 Clustering:聚合相似的数据
异常检测算法:用于检测数据中异常或罕见事件的方法
降维算法:是一种将高维数据压缩到低维数据的方法,丢失尽可能少的信息
3.1 聚类算法
获取没有标签的数据,并尝试自动将它们分组到集群中。
比如新闻归类、DNA聚类,用户分类等。
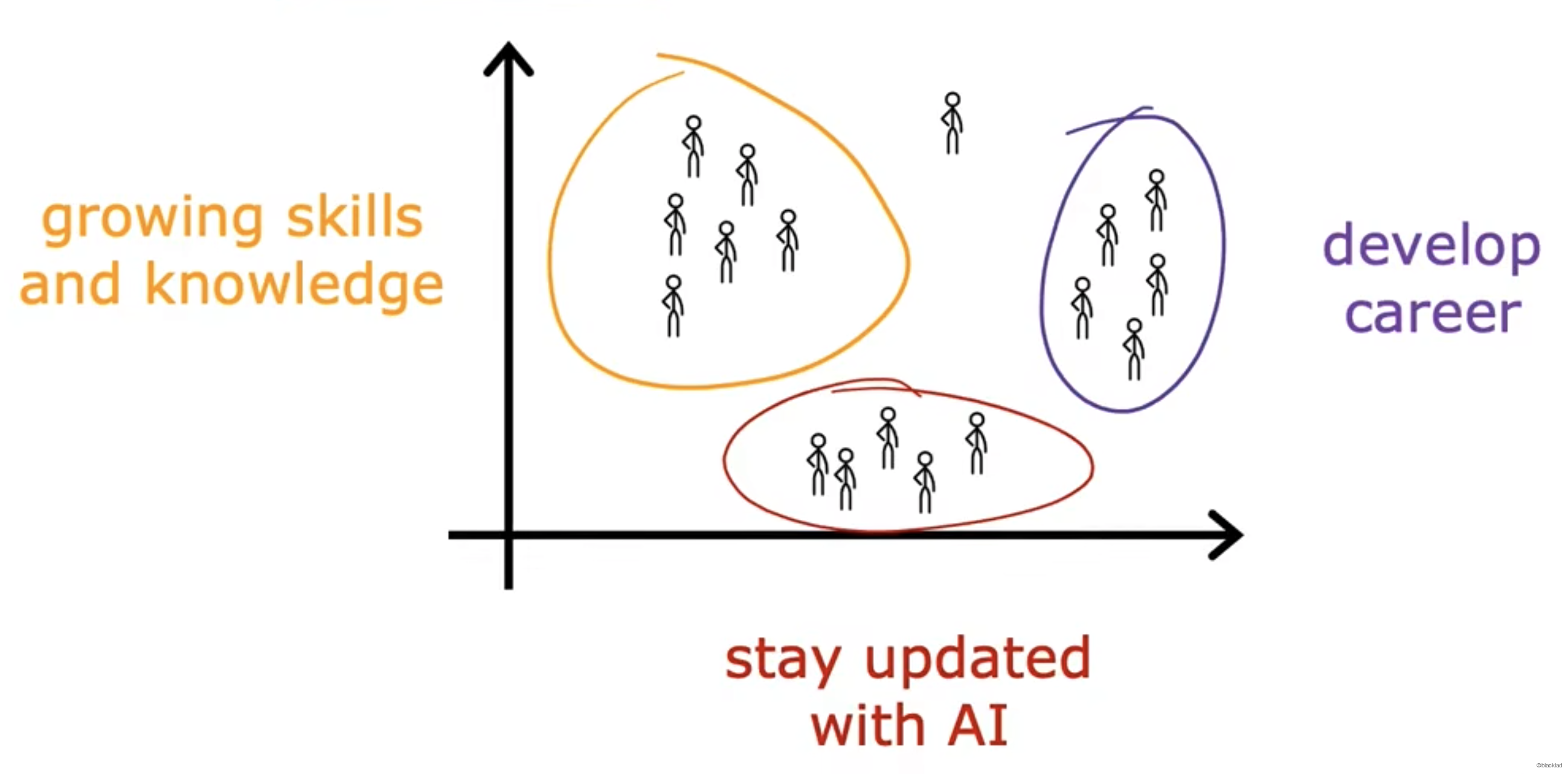
对用户进行聚类,自动分为不同的市场群体,以便更高效地为客户提供服务。