对于单一特征可以绘制图像观察模型是否出现过拟合现象,但是当特征增多时,难以通过图像直观的观察。通过模型评估,用系统的数据判断模型是否出现过拟合。
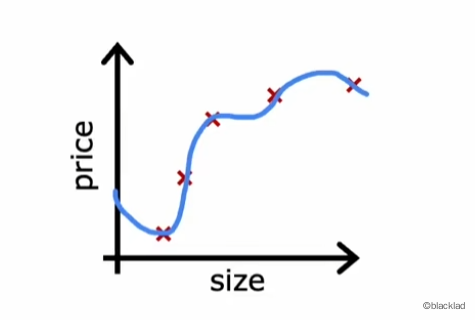
为了衡量模型的泛化能力,我们将原始的训练集进行拆分,如:
- 70%作为新的训练集(train set)用于正常训练
- 30%作为测试集(test set)用于测试
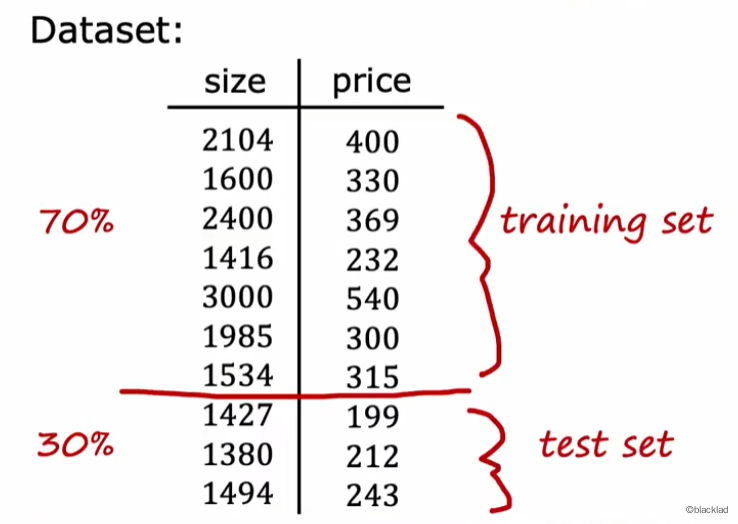
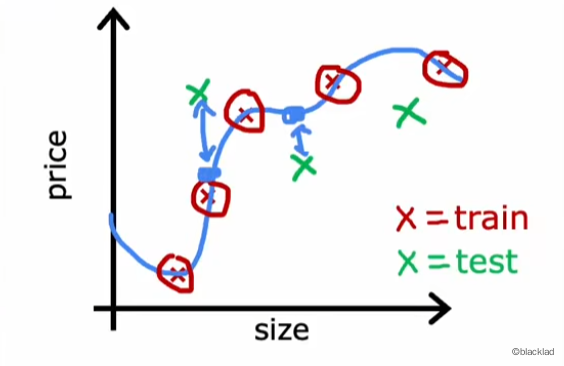
训练完成后,计算测试集的误差,通过对比训练集的误差和测试集的误差,就可以衡量模型的泛化能力。
在计算误差的时候,无需添加正则化项。
线性回归
Jtest(w,b)=2mtest1i=1∑mtest(fw,b(xtest(i))−ytest(i))2
逻辑回归
Jtest(w,b)=−mtest1i=1∑mtest[ytest(i)log(fw,b(xtest(i)))+(1−ytest(i))log(1−fw,b(xtest(i)))]
也可以使用测试集中的预测错误样本占比作为误差。
可以引入一个参数 d 表示多项式的阶数,可以得到不同的模型。先使用训练集的数据分别对每个模型训练,得到模型后,再用测试集计算出每个模型的误差。
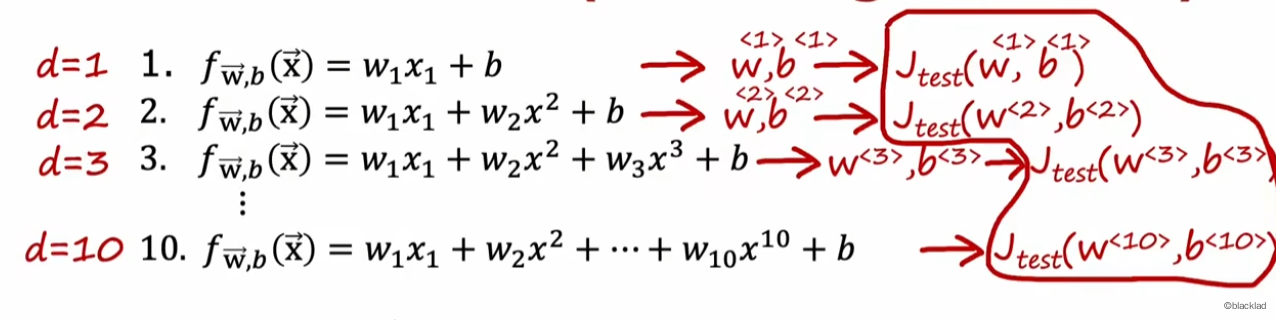
选择误差最小的模型作为最终的模型。
为了评估选择出来的模型的好坏。可以将数据集划分为3部分:训练集、验证集、测试集(可以为 6:2:2)。
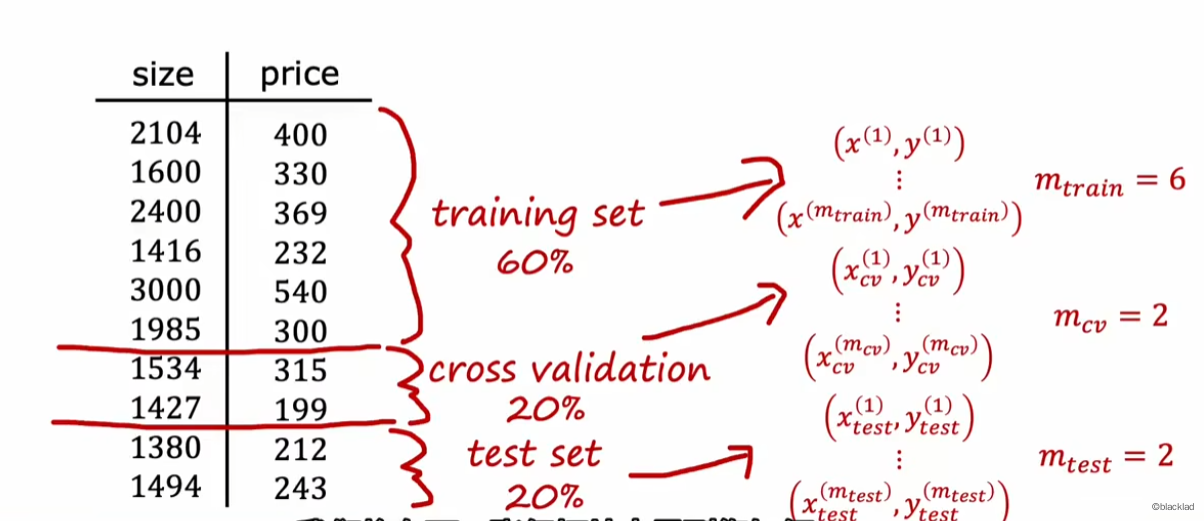
- 使用训练集进行训练,在不同模型上拟合出每个模型的最优w、b
- 使用交叉验证集选择模型,从拟合好的模型中选择一个最优的模型
- 使用测试集评估模型,得到这个模型的泛化能力

对于神经网络也可以使用交叉验证集。分别得到每个网络的验证机的误差,选择合适的网络模型。
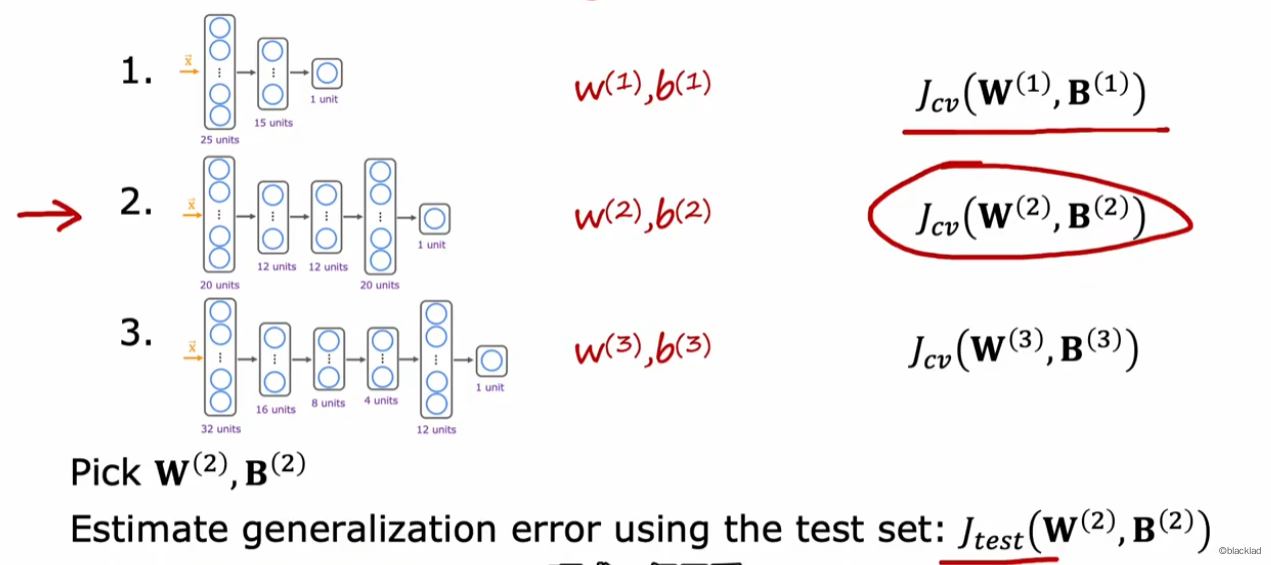
为了保证模型对新数据的泛化程度有公平的估计,在选择模型时,不能使用测试集对模型有任何评估。
