
高级优化方法
小于 1 分钟AIAI
高级优化方法
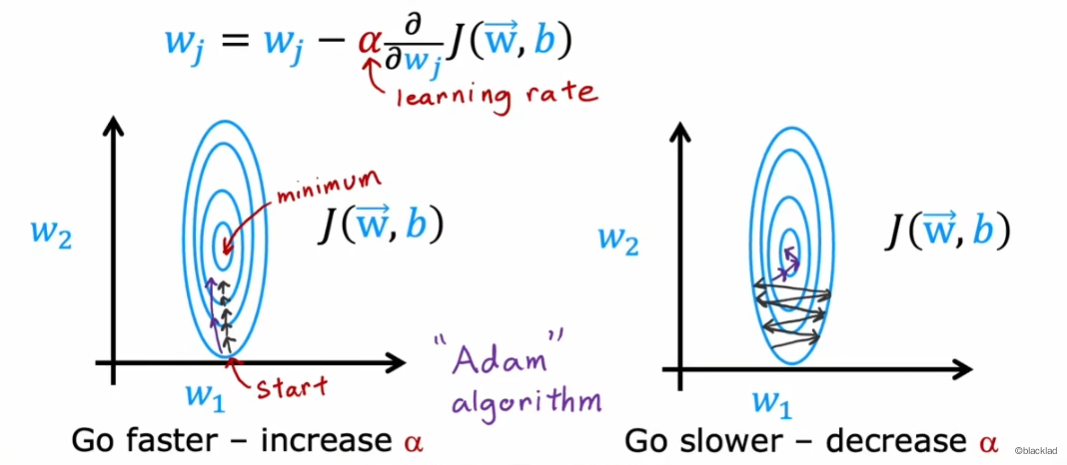
在梯度下降中,学习率 α 控制着每一步的大小
- 当学习率比较小的时候,如果梯度总是朝着一个方向的,我们希望学习率能够大一些
- 当学习率比较大的时候,梯度变化大,难以收敛到最小值,我们又希望学习率能够小一些。
1 Adam 算法
Adam(Adaptive Moment estimation) 算法可以动态的调整梯度下降过程中的学习率 ,用最短、最平滑的路径到达成本函数的最小值,通常比梯度下降方法更快。
Adam 算法没有使用一个全局的学习率,对于每个参数都有自己的学习率 。
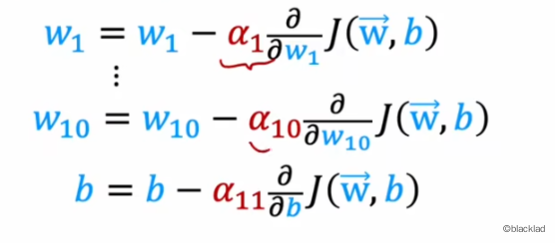
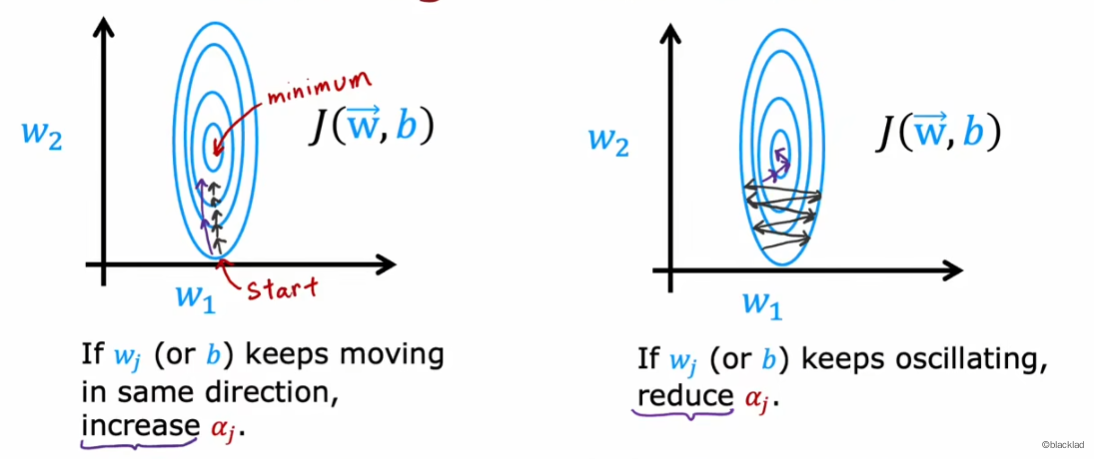
如果参数一直向同一个方向前进,就逐步增大该参数的学习率;若每次方向都不一样,来回振荡,就逐步减小学习率。
2 代码
在 compile 函数中可以指定使用 Adam 优化函数,同时使用参数 learning_rate=1e-3 指定初始学习率为0.001。
