
数据分组
大约 3 分钟PythonPythonPandas
数据分组
1 介绍
数据分组是一个非常强大的功能,允许你对数据集按照某些标准进行分组,然后对每个分组单独应用某些操作。这个过程通常被称为“split-apply-combine”策略,即首先“分组”(split)数据,然后“应用”(apply)某些函数,最后将结果“组合”(combine)在一起。
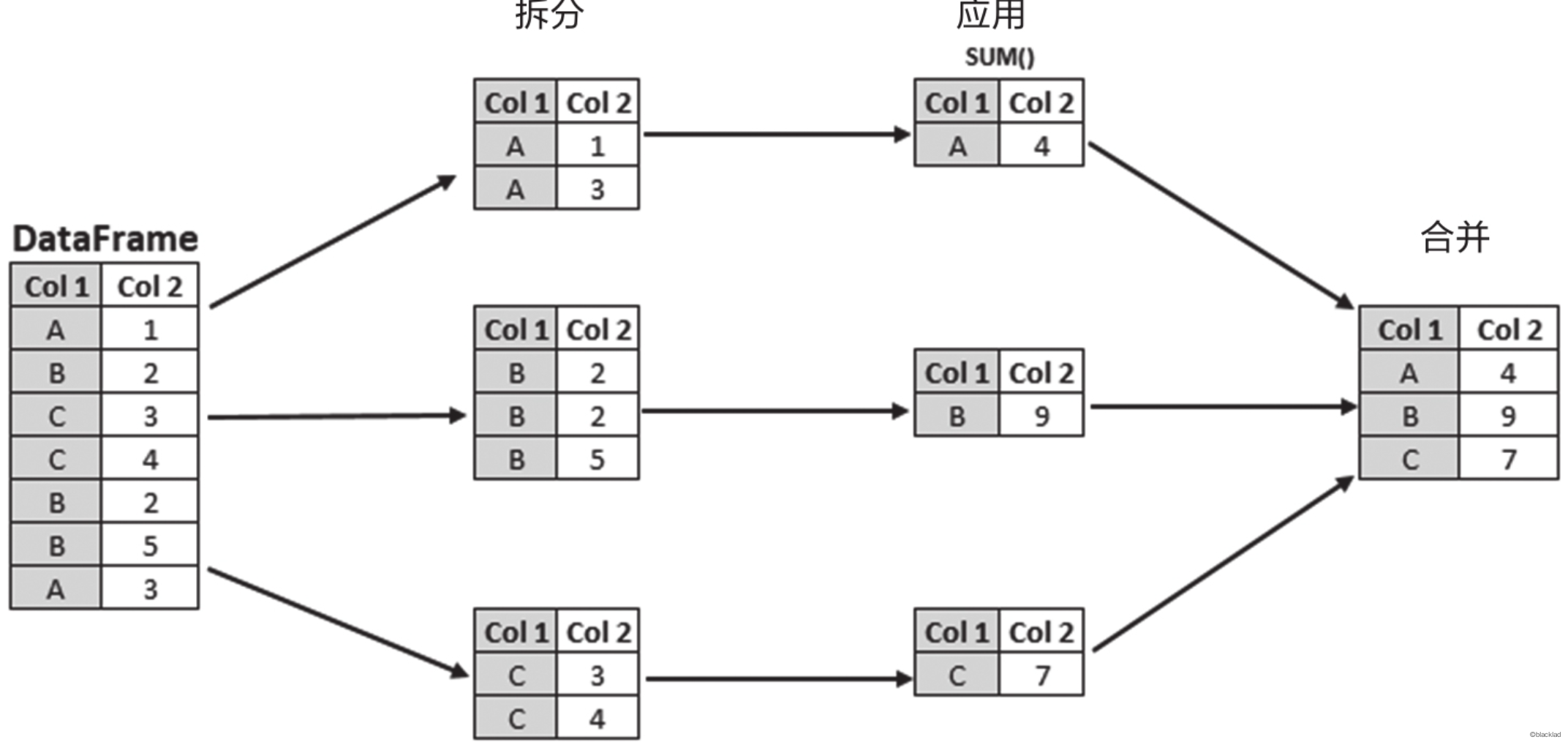
2 数据
import pandas as pd
# 创建 DataFrame
data = {
'姓名': ['Alice', 'Bob', 'Charlie', 'Alice', 'Bob', 'Charlie',
'Alice', 'Bob', 'Charlie', 'Alice', 'Bob', 'Charlie'],
'学期': ['一', '一', '一', '二', '二', '二',
'一', '一', '一', '二', '二', '二'],
'科目': ['Math', 'Math', 'Math', 'Math', 'Math', 'Math',
'English', 'English', 'English', 'English', 'English', 'English'],
'成绩': [85, 78, 92, 88, 76, 85, 90, 80, 88, 95, 82, 91]
}
df = pd.DataFrame(data)
print(df)
姓名 学期 科目 成绩
0 Alice 一 Math 85
1 Bob 一 Math 78
2 Charlie 一 Math 92
3 Alice 二 Math 88
4 Bob 二 Math 76
5 Charlie 二 Math 85
6 Alice 一 English 90
7 Bob 一 English 80
8 Charlie 一 English 88
9 Alice 二 English 95
10 Bob 二 English 82
11 Charlie 二 English 91
3 使用 groupby
Pandas 中的分组操作主要依赖于 groupby 方法,它将数据根据某些列的值进行分组,并返回一个 DataFrameGroupBy 对象。你可以对这个对象应用各种聚合函数、过滤条件、变换操作等。
3.1 单列分组
group = df.groupby('姓名')
print(group)
打印 groupby 结果,可以看到返回了一个DataFrameGroupBy对象。
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x7f7cf6b96250>
3.2 多列分组
df.groupby(['姓名', '科目'])
4 聚合操作
groupby 后你可以对分组数据应用各种聚合操作,如 sum()、mean()、count() 等。
grouped = df.groupby(['姓名', '科目'])
4.1 分组数据的均值
对于不能求均值的学期那列,就没有显示。
mean_values = grouped.mean()
print(mean_values)
成绩
姓名 科目
Alice English 92.5
Math 86.5
Bob English 81.0
Math 77.0
Charlie English 89.5
Math 88.5
4.2 分组数据的总和
sum_values = grouped.sum()
print(sum_values)
成绩
姓名 科目
Alice English 185
Math 173
Bob English 162
Math 154
Charlie English 179
Math 177
4.3 每个分组的计数
count_values = grouped.count()
print(count_values)
学期 成绩
姓名 科目
Alice English 2 2
Math 2 2
Bob English 2 2
Math 2 2
Charlie English 2 2
Math 2 2
5 自定义函数
我们还可以对分组后的数据应用自定义函数,比如计算每个学生在每个学期的成绩的最大值与最小值之差:
def score_range(group):
return group['成绩'].max() - group['成绩'].min()
res = grouped.apply(score_range)
print(res)
姓名 科目
Alice English 5
Math 3
Bob English 2
Math 2
Charlie English 3
Math 7
dtype: int64
6 数据过滤
使用 filter 方法筛选出那些某个科目的平均分超过90分的学生:
res = grouped.filter(lambda x: x['成绩'].mean() > 90)
print(res)
姓名 学期 科目 成绩
6 Alice 1 English 90
9 Alice 2 English 95
7 转换方法
通过 transform 对每个分组进行变换,并返回与原数据相同形状的结果。
# 首先使用 `transform` 得到每一行数据的总成绩
total = grouped['成绩'].transform('sum')
# 用每一行的成绩除以对应的总成绩
df['成绩百分比'] = df['成绩'] / total * 100
print(df)
姓名 学期 科目 成绩 成绩百分比
0 Alice 一 Math 85 49.132948
1 Bob 一 Math 78 50.649351
2 Charlie 一 Math 92 51.977401
3 Alice 二 Math 88 50.867052
4 Bob 二 Math 76 49.350649
5 Charlie 二 Math 85 48.022599
6 Alice 一 English 90 48.648649
7 Bob 一 English 80 49.382716
8 Charlie 一 English 88 49.162011
9 Alice 二 English 95 51.351351
10 Bob 二 English 82 50.617284
11 Charlie 二 English 91 50.837989