
Redis 复制
Redis 复制
可以通过 slaveof 命令让一个服务器去复制另外一个服务器,通过复制让主从服务器的数据保持一致。
1 旧版实现
通过同步和命令传播两个操作实现。
1.1 同步
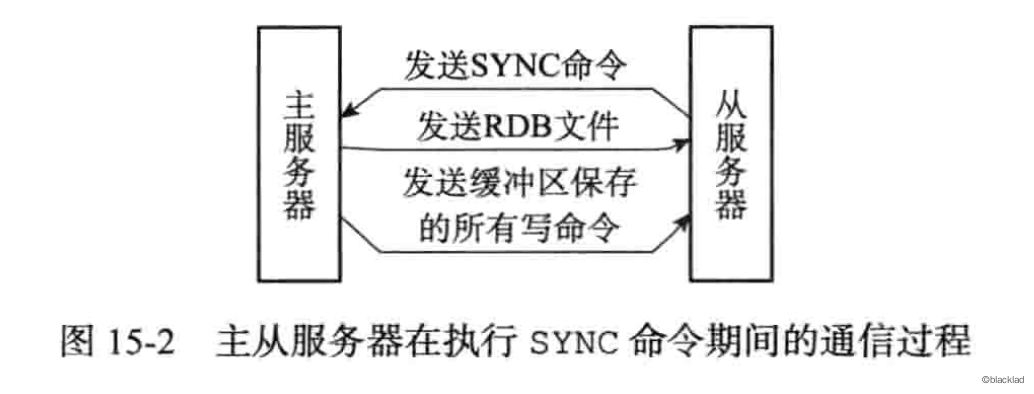
同步操作需要通过向主服务器发送 sync 命令完成。
- 发送
sync命令。 - 主服务器收到
sync命令后,执行bgsave命令,在后台生成一个RDB文件,并使用一个缓冲区记录从现在开始的所有写命令。 - 将生成的
RDB文件发送给从服务器,从服务器接收并载入这个RDB文件,将状态更新为主服务器执行bdsave命令时的状态。 - 主服务器将缓冲区中的所有写命令发送给从服务器执行,将从服务器的状态更新到主服务器当前的状态。
1.2 传播
同步完成成后,后续的写操作通过命令传播操作,即将主服务器执行的写操作在从服务器中再次执行达到一致。
3.3 缺点
对于断线后的重复制,从服务器重新发送 sync 命令从主服务器同步数据,主服务执行sync命令生成**完整 RDB **文件发送给从服务器,造成一些不必要的消耗。
2 新版实现
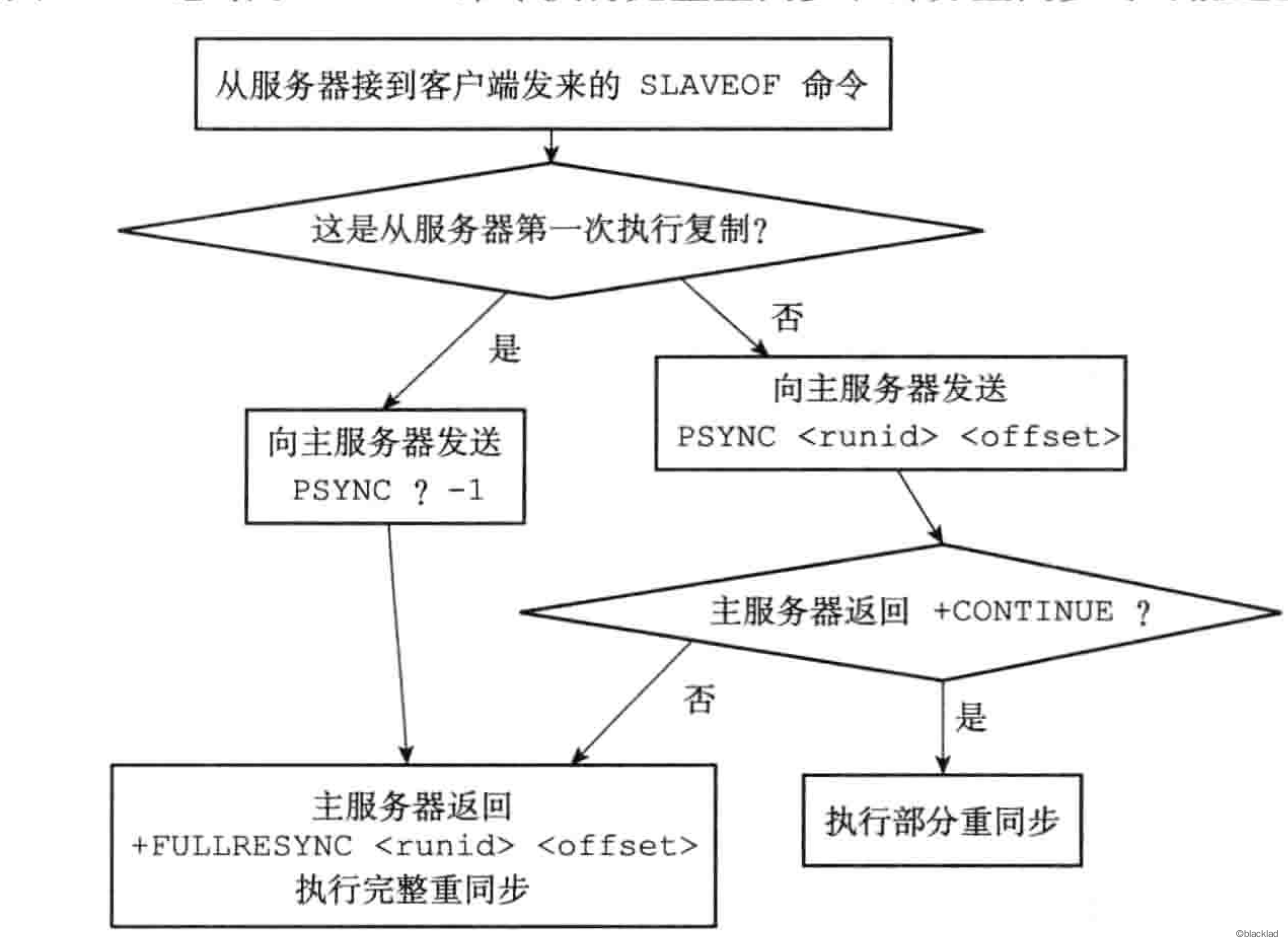
Redis 2.8 加入了 PSYNC 命令,具有完整同步和部分重同步两种模式。
完整同步和 SYNC 步骤相同,部分重同步则用于处理断线后复制情况,主服务器可以将短线过程中执行的写命令发送给从服务器同步。
2.1 复制偏移量
主从服务器都会维护一个复制偏移量。
主服务器每次想从服务器传播 N 个字节,就会将自己的偏移量加 N。
从服务器每次收到 N 个字节的数据,也会将自己的偏移量加 N。
通过判断主从服务器的便宜量判断是否处于一致状态。
从服务器在断线恢复以后,执行 PSYNC 命令,同时告诉当前的偏移量,主服务器根据偏移量判断执行重新同步。
2.2 积压缓冲区
主服务器中维护了一个固定长度的队列,在进行命令传播的时候也会往队列写入,因此主服务器的积压缓冲去里面会保存着一部分最近传播的写命令。
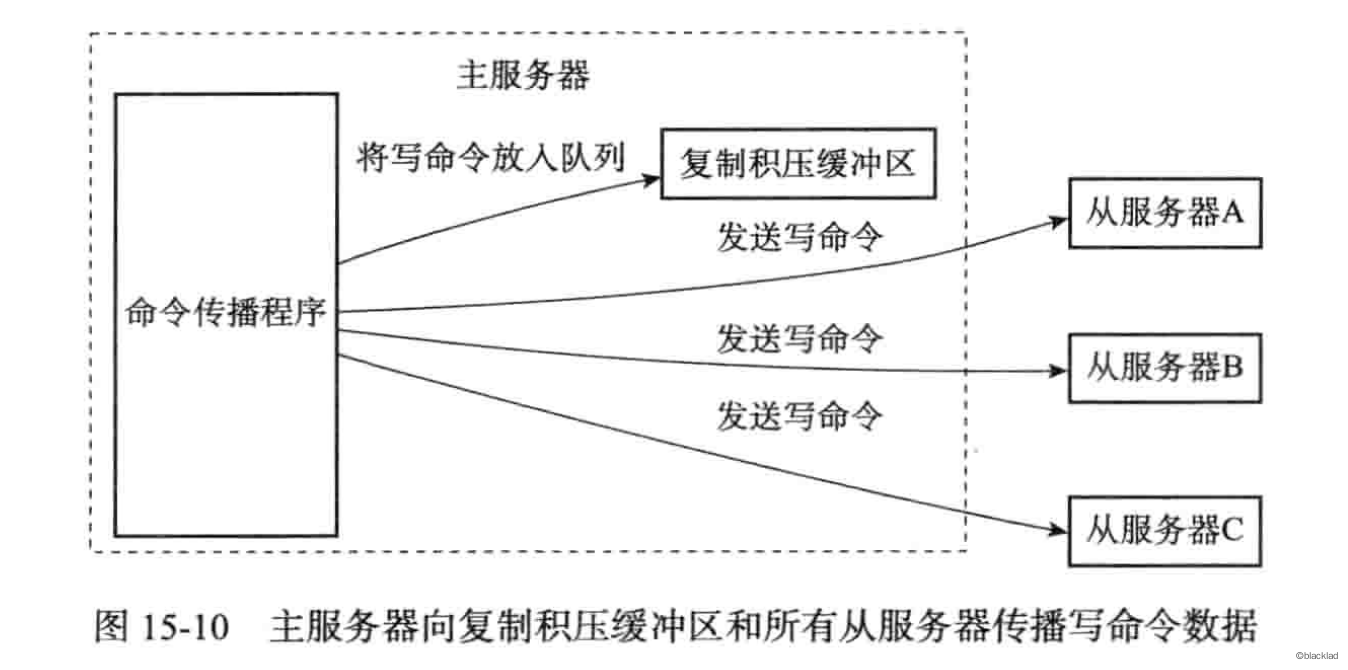
主服务器收到 PSYNC 命令后,会判断的从服务器的偏移量和积压缓冲区的偏移量判断是否执行部分同步操作或者完整同步操作。
如果执行部分同步操作,主服务器将缓冲区的指定位置偏移量之后的所有数据发送给从服务器。
2.3 服务器运行ID
每个 Redis 服务器在启动时都会生成一个运行 id,从服务器在同步时会保存主服务器的运行 id,在断线重连后,会将这个 id 发送给主服务器,主服务器根据id判断断线前连接的是否是当前服务器。
2.4 复制流程
优点:
- 高可靠性:一方面,采用双机主备架构,能够在主库出现故障时自动进行主备切换,从库提升为主库提供服务,保证服务平稳运行;另一方面,开启数据持久化功能和配置合理的备份策略,能有效的解决数据误操作和数据异常丢失的问题。
- 读写分离策略:从节点可以扩展主库节点的读能力,有效应对大并发量的读操作。
缺点:
- 故障恢复复杂,如果没有
RedisHA系统(需要开发),当主库节点出现故障时,需要手动将一个从节点晋升为主节点,同时需要通知业务方变更配置,并且需要让其它从库节点去复制新主库节点,整个过程需要人为干预,比较繁琐。 - 主库的写能力受到单机的限制,可以考虑分片。
- 主库的存储能力受到单机的限制,可以考虑
Pika。 - 原生复制的弊端在早期的版本中也会比较突出,如:Redis 复制中断后,
Slave会发起psync,此时如果同步不成功,则会进行全量同步,主库执行全量备份的同时可能会造成毫秒或秒级的卡顿;又由于COW机制,导致极端情况下的主库内存溢出,程序异常退出或宕机;主库节点生成备份文件导致服务器磁盘 IO 和 CPU (压缩)资源消耗;发送数 GB 大小的备份文件导致服务器出口带宽暴增,阻塞请求,建议升级到最新版本。